Study
Introduction
In our laboratory, we aim at mathematically elucidating various issues in information processing under uncertain environments. Many of the recent problems in this field can be formulated using large-scale stochastic models, and the key to solve these problems is to take advantage of the laws that emerge from the large-scale nature. An example of such attempts can be seen in information statistical mechanics, where the information mathematics of large-scale stochastic models is formulated using the tools developed in statistical mechanics. We are working on topics related to information statistical mechanics, statistical machine learning, deep learning and theoretical issues in data science. A characteristic of our research activities is "cross-disciplinary". Our research topics cover a wide range of academic fields such as information theory, communication theory, probability theory, statistical science, statistical mechanics, machine learning, among others.

Mathematics and Applications of Compressed Sensing
"Compressed sensing" is a new framework of information processing that focuses on the "sparsity" of data, and has attracted much attention in recent years from both mathematical and applied perspectives.
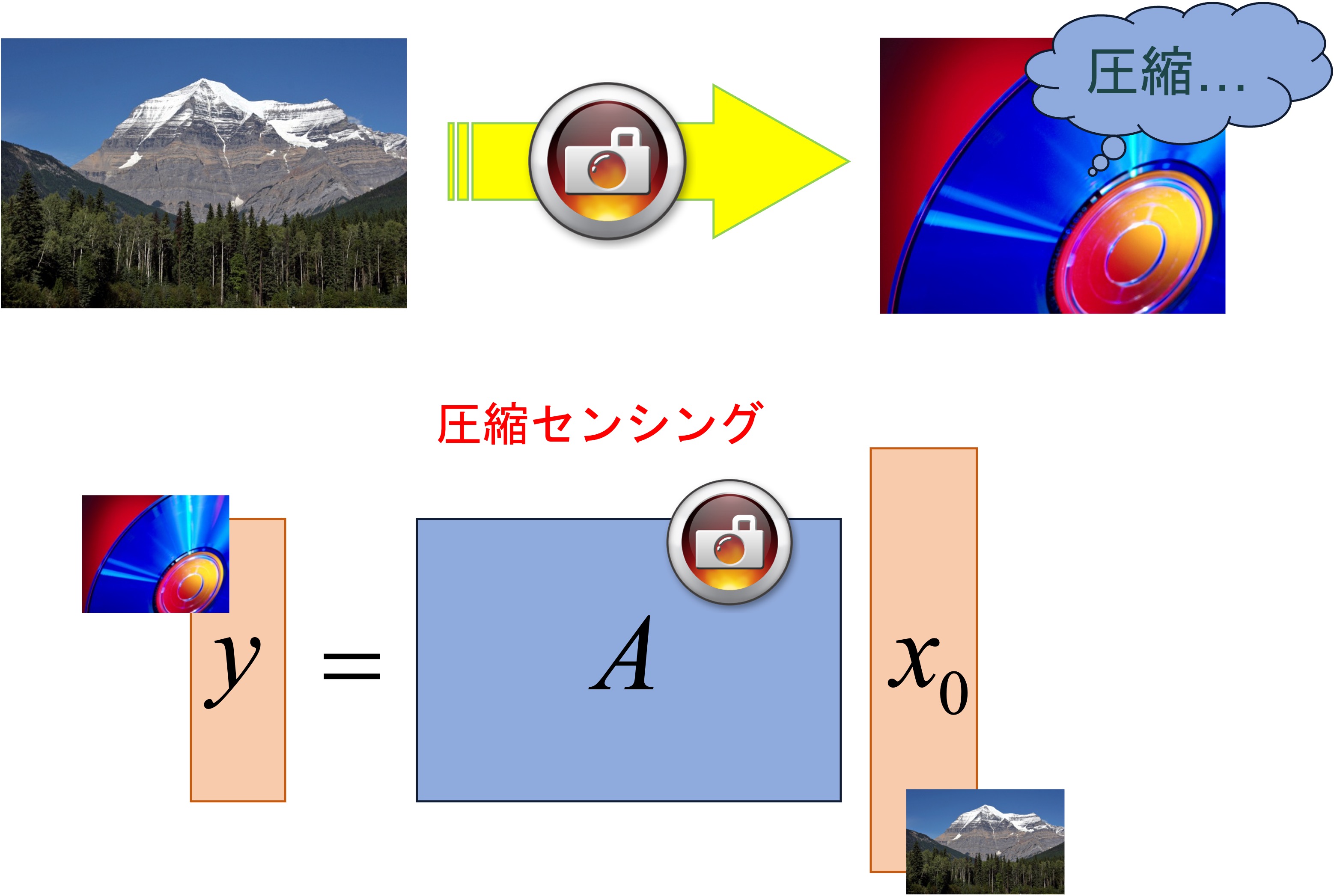
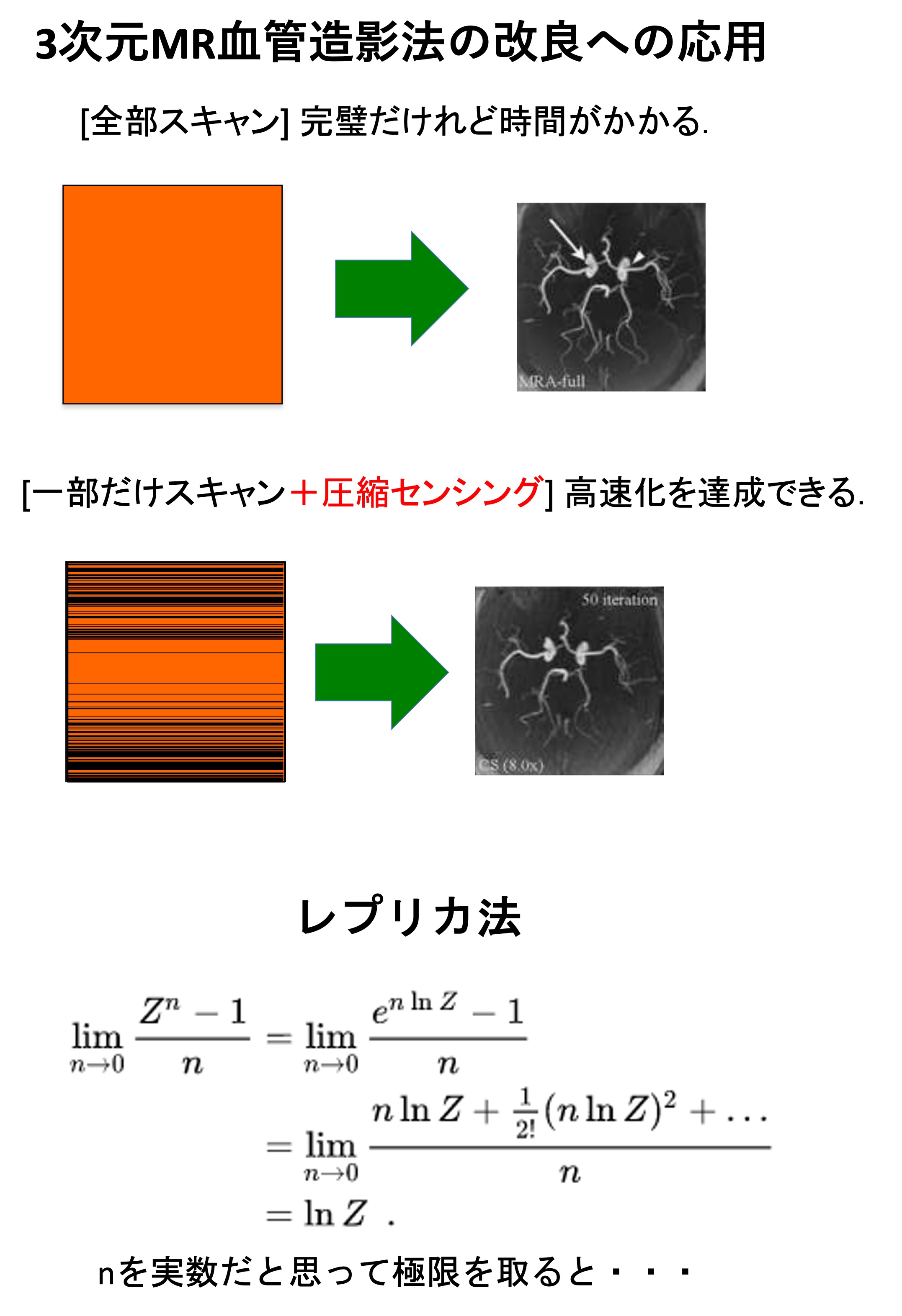
One of the most promising applications of compressed sensing is signal processing for magnetic resonance (MR) signals. Three major medical MRI companies have already begun marketing MRI systems that use compressive sensing. In collaboration with a laboratory at the Graduate School of Medicine, we have studied the application of compressed sensing to improve 3D MR angiography (article).
In collaboration with the Department of Systems Science and Biomedical Engineering, we also studied the application of MR spectral imaging to non-invasive measurement of the dynamics of substances in the body (Proc. ISMRM, 2018) (see video below). Furthermore, in collaboration with RIKEN and others, we have studied the application of low-rank tensor decomposition to protein NMR analysis (article).
Other studies include the application of compressed sensing to mass spectrometry. Mass spectrometry can measure small amounts of protein-containing samples with high sensitivity. It provides a very powerful tool for comprehensive analysis (metaproteomics) of cytoplasmic proteins, as well as those contained in the bacterial flora of the oral cavity, intestines, and so on. In collaboration with the Graduate School of Pharmaceutical Sciences, we are developing a tool to analyze mass spectrometry data using compressed sensing (patent pending) and deep learning.
We are also interested in mathematical properties of compressed sensing, such as the theoretical limits of reconstruction. We analyzed compressed sensing with the help of statistical mechanics methods. The reconstruction limits when employing Lp regularization were exhaustively studied using the replica method (article).
Furthermore, in order to clarify the performance of L1 regularization in the presence of observation noise, a detailed analysis was also conducted using the replica method. As a result, we found that the multi-step estimation, which had been used empirically, did indeed lead to improved performance and that the cross-validation method provided a reasonable choice of regularization coefficients. We also obtained an approximate formula to implement the cross-validation method with a low computational cost (article).
Information processing based on stochastic models
The problem of how to efficiently extract meaningful information from an environment with uncertainty is an issue that appears in many forms of information processing, including machine learning.
To address this issue, we are conducting cross-disciplinary and multifaceted research on methodologies for describing uncertainty in the environment by using probabilistic models, based on which inference, learning, and adaptation are performed. These attempts are from the standpoint of statistical science, information theory, statistical mechanics, and information geometry, which have attracted a lot of attention in recent years.
In addition to the general objective that results obtained in information processing are validated using stochastic models, we also study specific problems such as spatial data analysis, clustering of multidimensional data, information estimation in communication, reinforcement learning, game theory, and so on.
For example, Gaussian processes (GP) define a probability distribution over a function space. They are known for their high flexibility as well as ease of inference, and are used in a wide range of applications. They are also attracting attention as a model for discussing the limit of infinite width of multilayer neural networks.
We developed an approximate method to reduce the computational complexity of the GP regression (article), and worked on the resolution enhancement of multiple coarse-grained areal data (article).
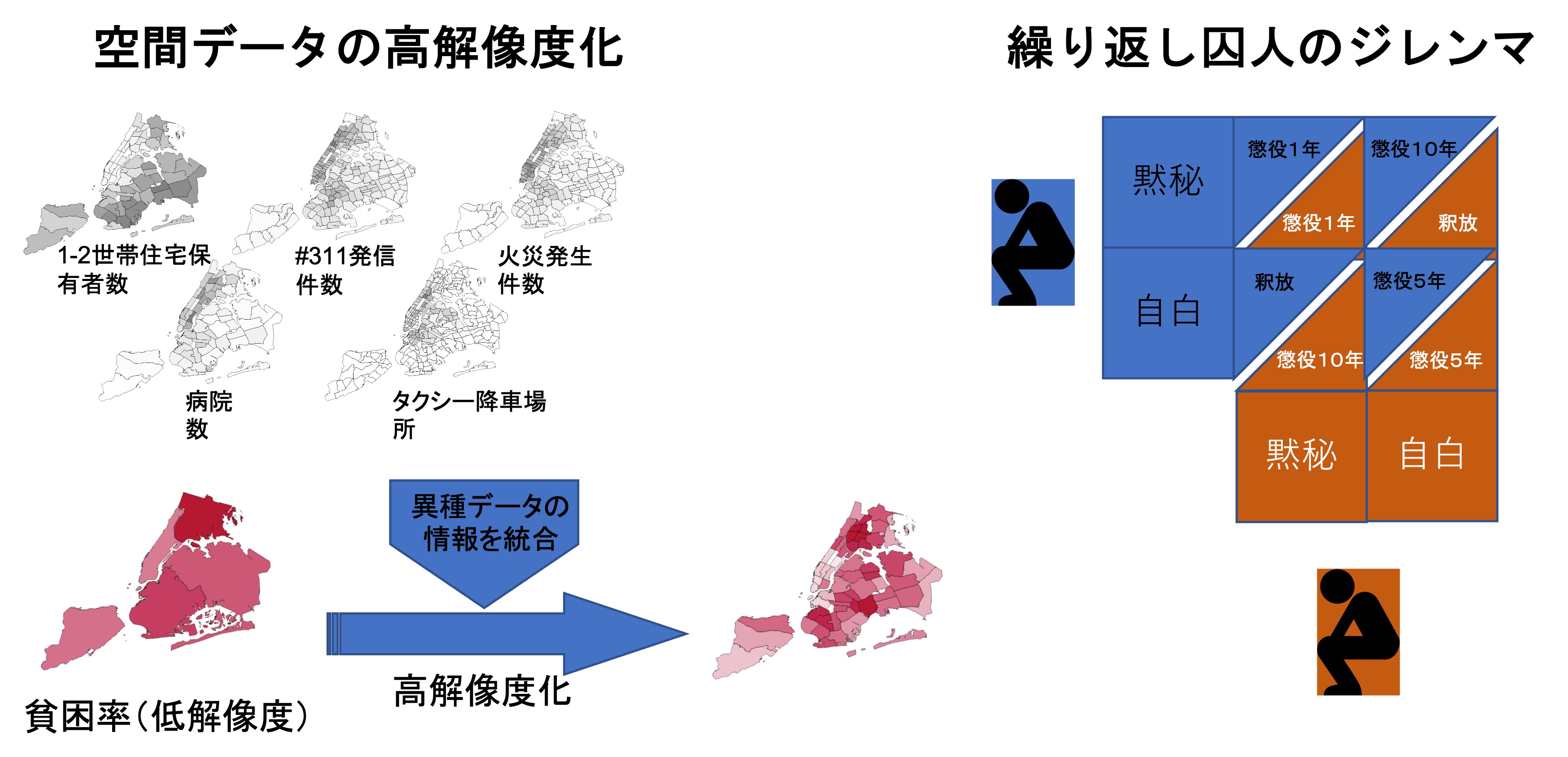
The "Prisoner's Dilemma" in game theory is a classic example of a situation in which the outcome of each individual’s rational choice of action (Nash equilibrium) is not optimal for the whole (Pareto optimum). A new strategy called the "zero-matrix formula strategy" was proposed by Press and Dyson in 2012 and has attracted a lot of attention. We generalized this zero-matrix strategy to multi-player games, and revealed a variety of algebraic properties (article).
We also study the inverse Ising problem. The Ising model describing magnetic materials in statistical mechanics can be regarded as a Markov random field model (which is used to model various tasks in image processing and computer vision).
The simplicity of the model allows for various analytical studies of inverse problems. We analyzed, using the replica method, whether the interaction network can be completely predicted in the inverse Ising problem with and without L1 and L2 regularization, and with multiple cost functions (pseudo-likelihood, mean squared error) (article).
Random Principal Component Analysis (rPCA) is known as a data- and dimensionality-compression method, reducing the data by random projection and then applying further the standard PCA. However, how much of the original information is retained during the procedure is still unclear. To approach this problem, we used the replica method to investigate how much information can be extracted in the above operation in a model called the spike model (=signal + noise) (article).
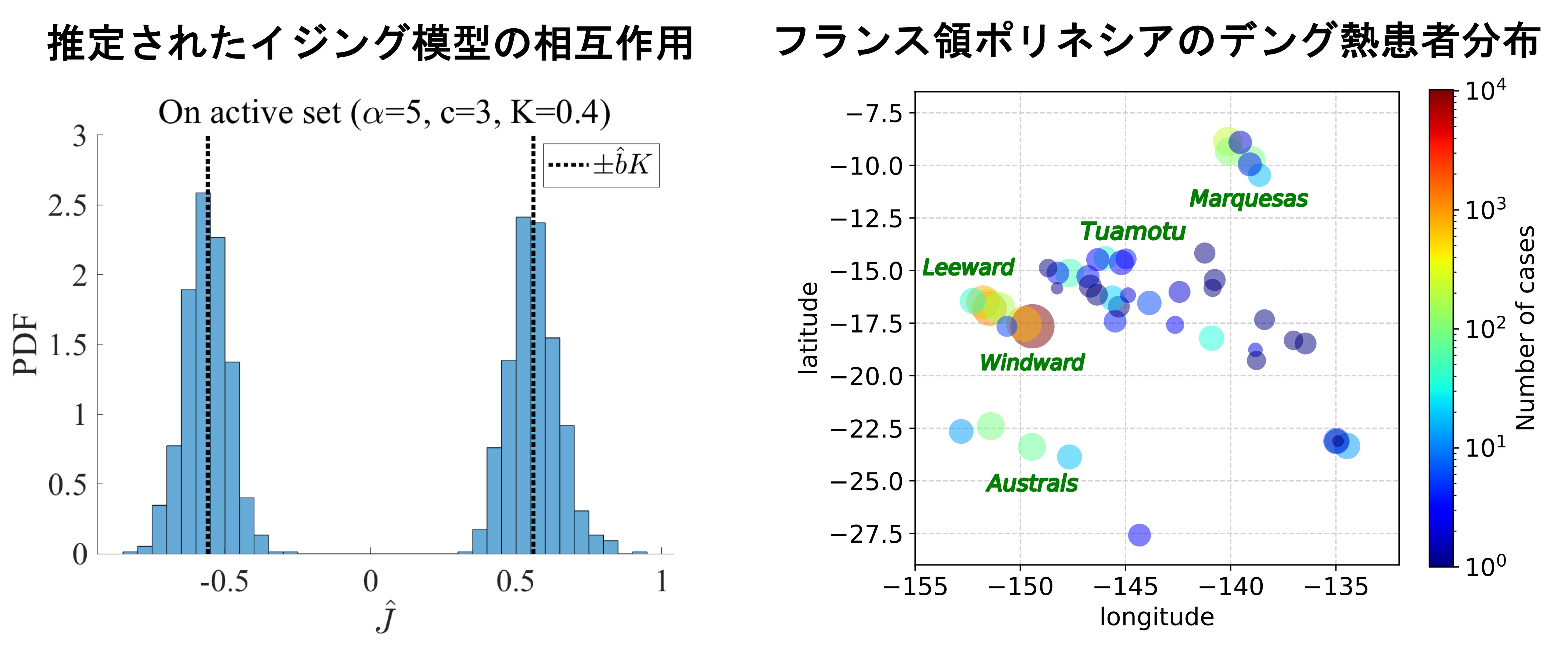
We also apply stochastic models to epidemiology. As seen in the recent news with the pandemic of COVID-19, estimating the number of asymptomatic patients (i.e., those who are infected but do not show symptoms) from the data at hand is an important issue.
For dengue in French Polynesia, we used Bayesian inference to estimate the number of asymptomatic individuals between 1979 and 2014 from the patient data during the same period (i.e., the number of symptomatic patients) (article).
Deep Learning from Mathematical viewpoint
We study issues related to deep learning from a mathematical perspective. Deep learning has been in the spotlight for more than a decade. Although deep learning has provided us with a flexible representation of hypotheses and the means to learn them, there are still many unsatisfactory answers to the questions of why deep learning works and why the various proposals related to deep learning are effective.
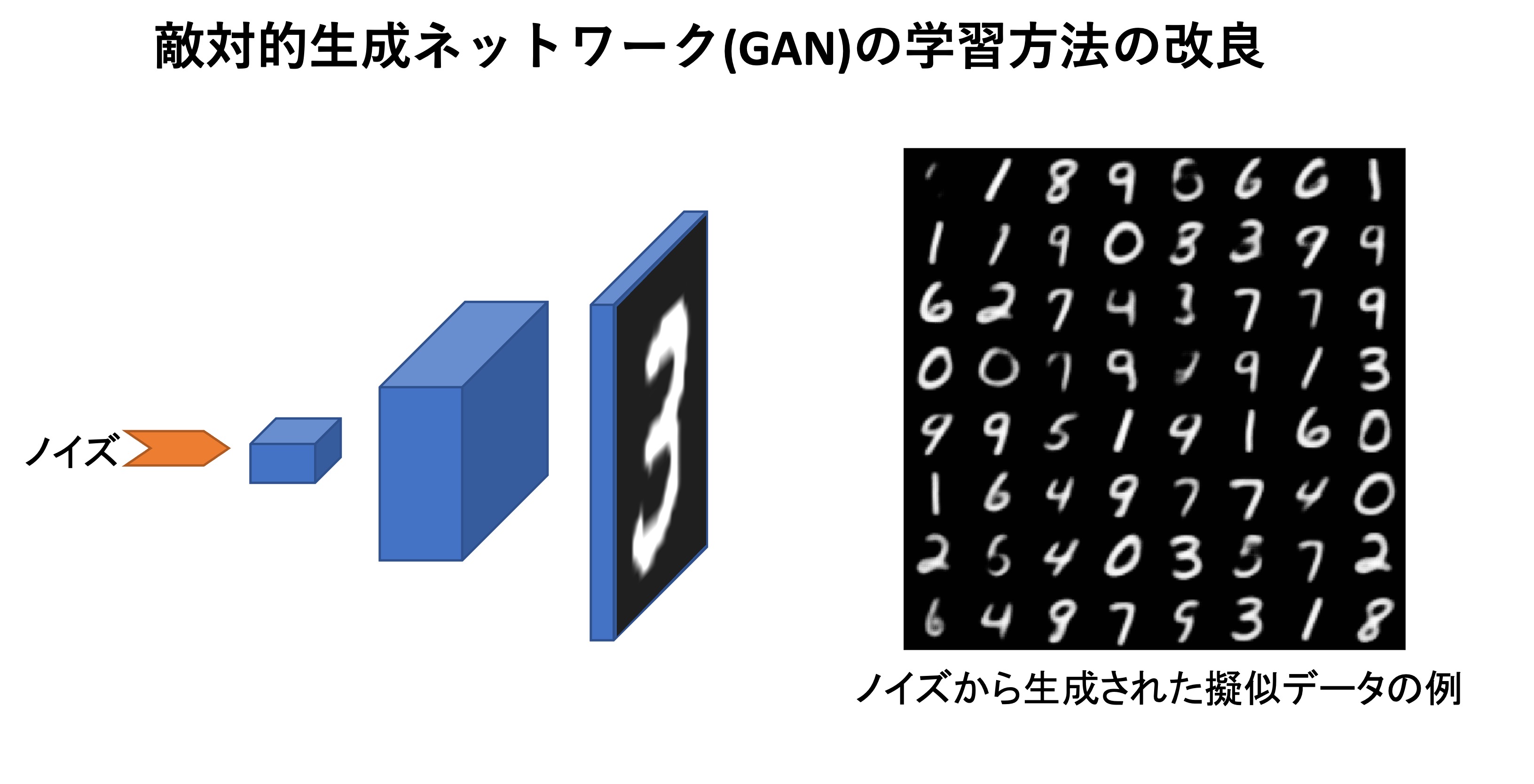
Our research interests include an analysis of stochastic gradient descent and a direct evaluation of the objective function of learning based on the optimal transport theory (article).
For the latter, we improved the learning method for a model called WGAN (a variant of adversarial generative networks or so-called GAN models based on optimal transport theory).
We are also working on the application of deep learning models (regarded as flexible representation systems of hypotheses) to various statistical data analyses, such as ordinal regression.
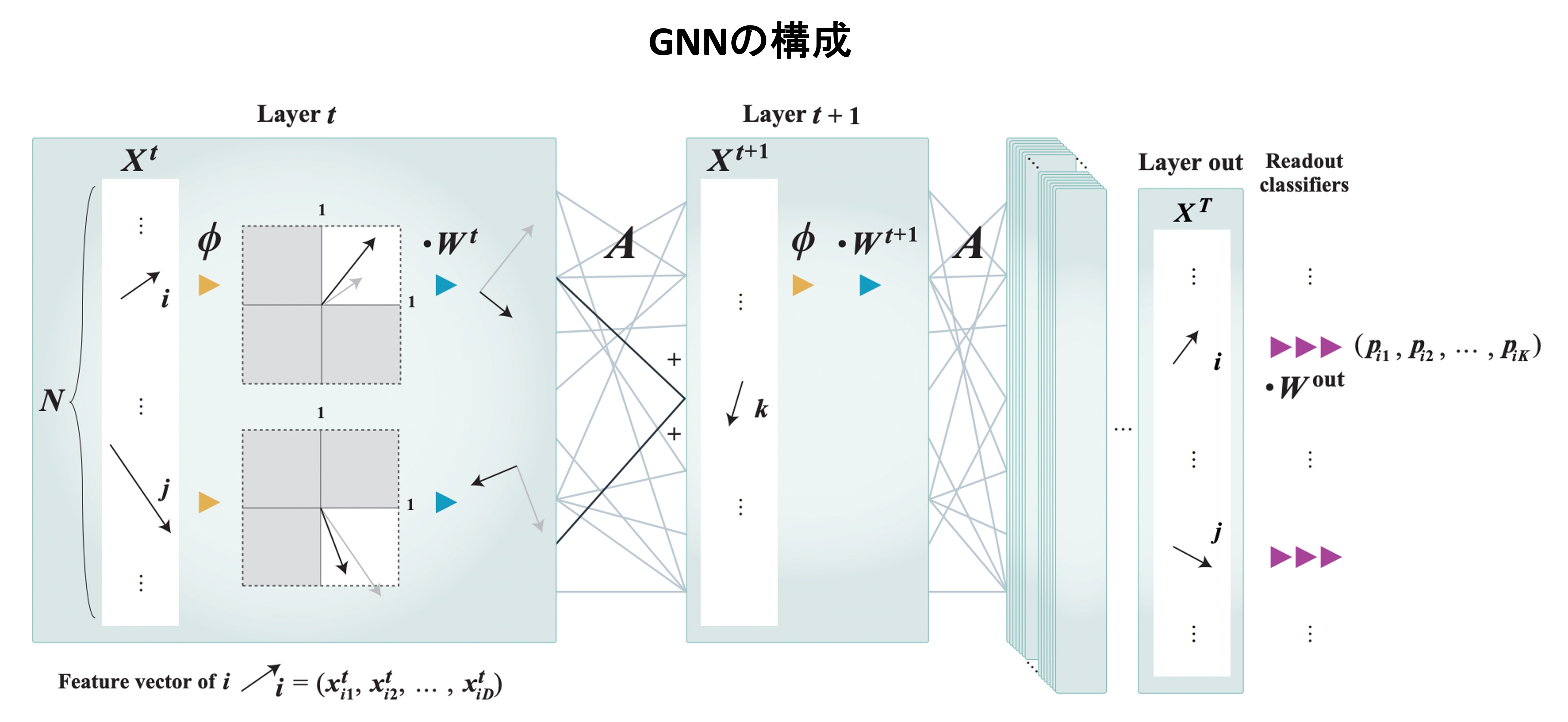
We evaluated the theoretical performance of graph partitioning using a Graph Neural Network (GNN: a graph data processing method based on deep learning) by employing the mean-field approximation from statistical mechanics.
We observed an agreement in a qualitative level between the mean-field result and the numerical experiment in a typical situation, suggesting the potential of the mean-field approximation for analyzing deep learning (article).